





The story behind Barracuda Active Threat Intelligence
A while ago at one of our brainstorming sessions, as teams discussed the next level of evolution for our products, it became evident that detection and protection against new and emerging threats required intensive data analysis at scale. The analysis would need to predict clients’ risk and do that efficiently and quickly if we wanted to prevent hostile action from taking place.
As we analyzed the requirements, we realized that to protect against advanced attackers like bots, we needed to build a platform that could analyze traffic for web sessions, correlate it with data across sessions, and for many things, across the entire customer base. We also figured out that many parts of the system needed to be real-time, some near real-time, and others could have a much longer analysis phase.
A few years ago we introduced Barracuda Advanced Threat Protection (BATP) for zero-day malware attack protection across the Barracuda product line. This capability—analyzing files to detect malware using multiple engines in addition to sandboxing—was introduced in Barracuda’s application security products to secure applications like order processing systems where files were uploaded by third parties. This was the first attempt to use a cloud-based layer for advanced analysis that would have been difficult to build into web application firewall appliances.
While the BATP cloud layer could handle millions of file scans, we needed a system that could store large amounts of meta information so it could be analyzed to figure out new and evolving threats. This started us on the journey toward the next threat intelligence platform.
How Active Threat Intelligence works
The Barracuda Active Threat Intelligence platform is our answer. The platform is built on a massive data lake, which can handle stream processing as well as batch processing of data. It processes millions of events per minute, across geographies, and provides intelligence that is used for detecting bots and client-side attacks, as well as providing information to protect against those threat vectors. Barracuda Active Threat Intelligence is built with an open architecture to be able to evolve rapidly to address newer threats.
Today, Barracuda Active Threat Intelligence platform receives data from the security engines in the Barracuda Web Application Firewall and WAF-as-a-Service, as well as other sources. As the events are received, they are augmented using crowd-sourced threat feeds and other intelligence databases. Detailed analysis of these events, both individually and as a part of a user session, is used to categorize the clients as humans or bots.
The data analysis pipelines use various engines and machine learning models to analyze multiple aspects of the traffic and reach their recommendations, which are finally reconciled to produce the final verdict.
Ways Active Threat Intelligence helps protect your apps
In addition to supporting all the analysis required for Advanced Bot Protection, the Active Threat Intelligence platform is being used for our latest offerings: Client-Side Protection and the Automated Configuration Engine.
Active Threat Intelligence tracks any external resources that may be used by the app, such as an external JavaScript or a stylesheet. Keeping track of external resources ensures that we are aware of the threat surface, and we can protect against attacks such as MageCart and more.
Because the meta data that is collected is extremely rich, we are able to derive additional information from it to assist administrators by providing configuration recommendations based on the real traffic coming to their apps.
This platform has been instrumental in helping us build the next generation of protection capabilities that our customers require. We continue to leverage this scalable platform to gather deep insights into traffic patterns, application consumption, and more. Stay tuned for blogs from our engineering teams that will talk about how we built Barracuda Advanced Threat Intelligence.

Anshuman Singh is Senior Director Product Management, Barracuda. Connect with him on LinkedIn here.
The evolution of the data pipeline
The data pipeline is the central pillar of modern data-intensive applications. In the first post of this series, we’ll take a look at the history of the data pipeline and how these technologies have evolved over time. Later we’ll describe how we are leveraging some of these systems at Barracuda, things to consider when evaluating components of the data pipeline, and novel example applications to help you get started with building and deploying these technologies.

MapReduce
In 2004 Jeff Dean and Sanjay Ghemawat of Google published MapReduce: Simplified Data Processing on Large Clusters. They described MapReduce as:
“[…] a programming model and an associated implementation for processing and generating large data sets. Users specify a map function that processes a key/value pair to generate a set of intermediate key/value pairs, and a reduce function that merges all intermediate values associated with the same intermediate key.”
With the MapReduce model, they were able to simplify the parallelized workload of generating Google’s web index. This workload was scheduled against a cluster of nodes and offered the ability to scale to keep up with the growth of the web.
An important consideration of MapReduce is how and where data is stored across the cluster. At Google this was dubbed the Google File System (GFS). An open-source implementation of GFS from the Apache Nutch project was ultimately folded into an open-source alternative to MapReduce called Hadoop. Hadoop emerged out of Yahoo! in 2006. (Hadoop was named by Doug Cutting after a toy elephant that belonged to his son.)
Apache Hadoop: An open source implementation of MapReduce
![]()
Hadoop was met with wide popularity, and soon developers were introducing abstractions to describe jobs at a higher level. Where the inputs, mapper, combiner, and reducer functions of jobs were previously specified with much ceremony (usually in plain Java), users now had the ability to build data pipelines using common sources, sinks, and operators with Cascading. With Pig, developers specified jobs at an even higher level with an entirely new domain-specific language called Pig Latin. See word count in Hadoop, Cascading (2007), and Pig (2008) for comparison.
Apache Spark: A unified analytics engine for large-scale data processing
In 2009 Matei Zaharia began work on Spark at the UC Berkeley AMPLab. His team published Spark: Cluster Computing with Working Sets in 2010, which described a method for reusing a working set of data across multiple parallel operations, and released the first public version in March of that year. A follow-on paper from 2012 entitled Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing won Best Paper at the USENIX Symposium on Networked Systems Design and Implementation. The paper describes a novel approach called Resilient Distributed Datasets (RDDs), which enable programmers to leverage in-memory computations to achieve orders of magnitude performance increases for iterative algorithms like PageRank or machine learning over the same type of jobs when built on Hadoop.
Along with performance improvements for iterative algorithms, another major innovation that Spark introduced was the ability to perform interactive queries. Spark leveraged an interactive Scala interpreter to allow data scientists to interface with the cluster and experiment with large data sets much more rapidly than the existing approach of compiling and submitting a Hadoop job and waiting for the results.
A problem persisted, however, which is that the input into these Hadoop or Spark jobs only considers data from a bounded source (it does not consider new incoming data at runtime). The job is aimed at an input source, it determines how to decompose the job into parallelizable chunks or tasks, it executes the tasks across the cluster simultaneously, and finally, it combines the results and stores the output somewhere. This worked great for jobs like generating PageRank indexes or logistic regression, but it was the wrong tool for a vast number of other jobs that need to work against an unbounded or streaming source like click-stream analysis or fraud prevention.
Apache Kafka: A distributed streaming platform
In 2010 the engineering team at LinkedIn was undertaking the task of rearchitecting the underpinnings of the popular career social network [A Brief History of Kafka, LinkedIn’s Messaging Platform]. Like many websites, LinkedIn transitioned from a monolithic architecture to one with interconnected microservices — but adopting a new architecture based on a universal pipeline built upon a distributed commit log called Kafka enabled LinkedIn to rise to the challenge of handling event streams in near real-time and at considerable scale. Kafka was so-named by LinkedIn principal engineer Jay Kreps because it was “a system optimized for writing,” and Jay was a fan of the work of Franz Kafka.
The primary motivation for Kafka at LinkedIn was to decouple the existing microservices such that they could evolve more freely and independently. Previously, whatever schema or protocol was used to enable cross-service communication had bound the coevolution of services. The infrastructure team at LinkedIn realized that they needed more flexibility to evolve services independently. They designed Kafka to facilitate communication between services in a way that could be asynchronous and message-based. It needed to offer durability (persist messages to disk), be resilient to network and node failure, offer near real-time characteristics, and scale horizontally to handle growth. Kafka met these needs by delivering a distributed log (see The Log: What every software engineer should know about real-time data's unifying abstraction).
By 2011 Kafka was open-sourced, and many companies were adopting it en masse. Kafka innovated on previous similar message queue or pub-sub abstractions like RabbitMQ and HornetQ in a few key ways:
- Kafka topics (queues) are partitioned to scale out across a cluster of Kafka nodes (called brokers).
- Kafka leverages ZooKeeper for cluster coordination, high-availability, and failover.
- Messages are persisted to disk for very long durations.
- Messages are consumed in order.
- Consumers maintain their own state regarding offset of last consumed message.
These properties free producers from having to keep state regarding the acknowledgment of any individual message. Messages could now be streamed to the filesystem at a high rate. With consumers responsible for maintaining their own offset into the topic, they could handle updates and failures gracefully.
Apache Storm: Distributed real-time computation system
Meanwhile, in May of 2011, Nathan Marz was inking a deal with Twitter to acquire his company BackType. BackType was a business that “built analytics products to help businesses understand their impact on social media both historically and in real-time” [History of Apache Storm and Lessons Learned]. One of the crown jewels of BackType was a real-time processing system dubbed “Storm.” Storm brought an abstraction called a “topology” whereby stream operations were simplified in a similar nature to what MapReduce had done for batch processing. Storm became known as “the Hadoop of real-time” and quickly shot to the top of GitHub and Hacker News.
Apache Flink: Stateful computations over data streams
Flink also made its public debut in May 2011. Owing its roots to a research project called “Stratosphere” [http://stratosphere.eu/], which was a collaborative effort across a handful of German universities. Stratosphere was designed with the goal “to improve the efficiency of massively parallel data processing on Infrastructure as a Service (IaaS) platforms” [http://www.hpcc.unical.it/hpc2012/pdfs/kao.pdf].
Like Storm, Flink provides a programming model to describe dataflows (called “Jobs” in Flink parlance) that include a set of streams and transformations. Flink includes an execution engine to effectively parallelize the job and schedule it across a managed cluster. One unique property of Flink is that the programming model facilitates both bounded and unbounded data sources. This means that the difference in syntax between a run-once job that sources data from a SQL database (what may have traditionally been a batch job) versus a run-continuously job operating upon streaming data from a Kafka topic is minimal. Flink entered the Apache incubation project in March 2014 and was accepted as a top-level project in December 2014.
In February of 2013, the alpha version of Spark Streaming was released with Spark 0.7.0. In September of 2013, the LinkedIn team open sourced their stream processing framework “Samza” with this post.
In May of 2014 Spark, 1.0.0 was released, and it included the debut of Spark SQL. Although the current version of Spark at the time only offered streaming capability by splitting a data source into “micro-batches,” the groundwork was in place for executing SQL queries as streaming applications.
Apache Beam: A unified programming model for both batch and streaming jobs
In 2015 a collective of engineers at Google released a paper entitled The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing. An implementation of the Dataflow model was made commercially available on Google Cloud Platform in 2014. The core SDK of this work, as well as several IO connectors and a local runner, were donated to Apache and became the initial release of Apache Beam in June of 2016.
One of the pillars of the Dataflow model (and Apache Beam) is that the representation of the pipeline itself is abstracted away from the choice of execution engine. At the time of writing, Beam is able to compile the same pipeline code to target Flink, Spark, Samza, GearPump, Google Cloud Dataflow, and Apex. This affords the user the option to evolve the execution engine at a later time without altering the implementation of the job. A “Direct Runner” execution engine is also available for testing and development in the local environment.
In 2016 the Flink team introduced Flink SQL. Kafka SQL was announced in August 2017, and in May of 2019, a collection of engineers from Apache Beam, Apache Calcite, and Apache Flink delivered “One SQL to Rule Them All: An Efficient and Syntactically Idiomatic Approach to Management of Streams and Tables” towards a unified streaming SQL.
Where we’re headed
The tools available to software architects designing the data pipeline continue to evolve at an increasing velocity. We’re seeing workflow engines like Airflow and Prefect integrating systems like Dask to enable users to parallelize and schedule massive machine learning workloads against the cluster. Emerging contenders like Apache Pulsar, and Pravega are competing with Kafka to take on the storage abstraction of the stream. We’re also seeing projects like Dagster, Kafka Connect, and Siddhi integrating existing components and delivering novel approaches to visualizing and designing the data pipeline. The rapid pace of development in these areas makes it a very exciting time to build data-intensive applications.
If working with these kinds of technologies is interesting to you then we encourage you to get in touch! We’re hiring across multiple engineering roles and in multiple locations.

Robert Boyd is a Principal Software Engineer at Barracuda Networks. His current area of focus is on secure storage and search of email at scale.
Reader favorites from 2021
The end of the year is always a great time to show off some of our favorite content. These are the most popular Barracuda blog posts of 2020. We hope you enjoy them!
Ransomware and data breaches
- How hackers use phishing in ransomware attacks
- Top concerns healthcare organizations have about Office 365 backup
- 3 critical steps to protecting against ransomware
- Colonial Pipeline cyberattack reveals economic impact of ransomware
Research
Special Reports
- The state of network security in 2021
- The state of application security in 2021
- Cloud networks: Shifting into hyperdrive
- The state of Office 365 backup
- Insights into the growing number of automated attacks
Below the Surface
- Below the Surface: Why you need a cloud-native backup strategy
- Below the Surface: Advancing Women in Technology
- Below the Surface: Secure Access Service Edge with Sinan Eren
Barracuda
- Barracuda named a Visionary in the 2021 Gartner® Magic Quadrant
 for Network Firewalls
for Network Firewalls - Barracuda honored by Comparably for Best Company Culture
- 3 exciting product innovations announced at Secured.21
- Behind the scenes of the Barracuda Microsoft collaboration on Cloud-to-Cloud Backup
- Barracuda named to CRN’s 2021 Security 100 List
- Barracuda wins Best Customer Service in the 2021 SC Awards
Old favorites
Some questions never go away. Why can’t I use my personal email for work? What do you mean this spam isn’t spam? These posts are reader favorites year after year after year.
- The business risks of personal email accounts
- Ham v Spam: What’s the difference
- Threat Vectors – what are they and why do you need to know about them?
Looking forward to 2022
We’ll have more great content from our experts, including Olesia, Tushar, Anastasia, Jonathan, Fleming, and others. We publish several times a week, and If you’d like to get notified when we have new content please subscribe to our blog to get email summaries of the latest posts. New episodes of Below the Surface are broadcast every few weeks, and you can view the archived episodes on our website.
Best wishes for a happy new year, from all of us at Barracuda.

Christine Barry is Senior Chief Blogger and Social Media Manager at Barracuda. Prior to joining Barracuda, Christine was a field engineer and project manager for K12 and SMB clients for over 15 years. She holds several technology and project management credentials, a Bachelor of Arts, and a Master of Business Administration. She is a graduate of the University of Michigan.
Connect with Christine on LinkedIn here.
Highly scalable event logging on AWS
Most applications generate configuration events and access events. It is important for administrators to have visibility into these events. The Barracuda Email Security Service provides transparency and visibility into many of these events to help administrators fine-tune and understand the system. For example, knowing who logged into the account and when. Or knowing who added, changed, or deleted the configuration of a particular policy.
To build this distributed and searchable system, many questions come to mind, such as:
- How should you write these logs from all the applications, services, and machines to a central location?
- What should the standard format of the log files be?
- How long should you retain these logs?
- How should you correlate events from different applications?
- How do you provide a simple and quick searching mechanism via a user interface for the administrator?
- How do you make these logs available via an API?
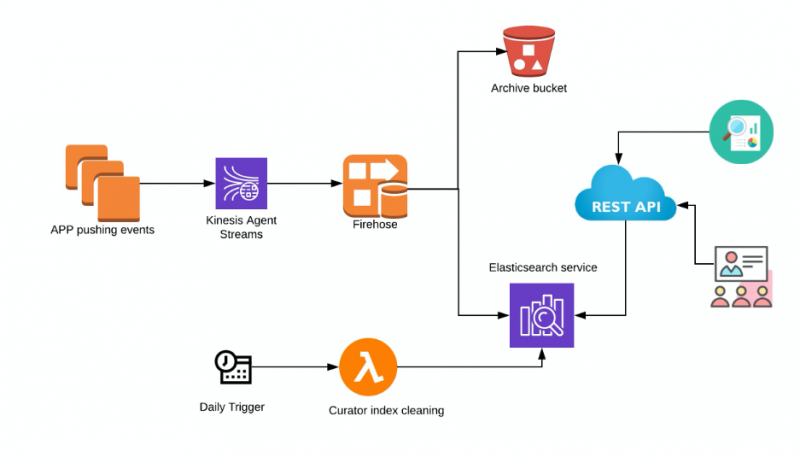
When you think of a distributed search engine, the first thing that comes to mind is Elasticsearch. It is highly scalable with near real-time search and available as a fully managed service in AWS. So, the journey started with the thinking of storing these event logs in Elasticsearch and all the different applications pushing logs to Elasticsearch using Kinesis Data Firehose.
Components involved in this architecture
- Kinesis Agent – Amazon Kinesis Agent is a standalone Java software application that offers an easy way to collect and send data to Kinesis Data Firehose. The agent continuously monitors event log files on EC2 Linux instances and sends them to the configured Kinesis Data Firehose delivery stream. The agent handles file rotation, checkpointing, and retry upon failures. It delivers all of your data in a reliable, timely, and simple manner. Note: If the application that needs to write to Kinesis Firehose is a Fargate container, you will need a Fluentd container. However, this article focuses on applications running on Amazon EC2 instances.
- Kinesis Data Firehose – Amazon Kinesis Data Firehose direct put method can write the JSON formatted data into Elasticsearch. This way it doesn’t store any data on the stream.
- S3 – An S3 bucket can be used to back up either all records or records that fail to be delivered to Elasticsearch. Lifecycle policies can also be set to auto-archive logs.
- Elasticsearch – Elasticsearch hosted by Amazon. Kibana access can be enabled to help query and search the logs for any debugging purpose.
- Curator – AWS recommends using Lambda and Curator to manage the indices and snapshots of the Elasticsearch cluster. AWS has more details and sample implementation that can be found here
- REST API interface – You can create an API as an abstraction for Elasticsearch which integrates well with the User interface. API-driven microservice architectures are proven to be the best in many aspects such as security, compliance, and integration with other services.
Scaling
- Kinesis Data Firehose: By default, firehose delivery streams can scale up to 1,000 records/sec or 1MiB/sec for US East (Ohio). This is a soft limit and can be increased up to 10,000 records/sec. This is region specific.
- Elasticsearch: The Elasticsearch cluster can be scaled both in terms of storage and compute power on AWS. Version upgrades are also possible. Amazon ES uses a blue/green deployment process when updating domains. This means that the number of nodes in the cluster might temporarily increase while your changes are applied.
Advantages of this Architecture
- The pipeline architecture is effectively completely managed and requires very little maintenance.
- If the Elasticsearch cluster fails, Kinesis Firehose can retain records for up to 24 hours. In addition, records that fail to deliver are also backed up to S3.
The chances for data loss are low with these options available.
- Fine-grained access control is possible to both Kibana and Elasticsearch API through IAM policies.
Shortcomings
- Pricing needs to be carefully considered and monitored. The Kinesis Data Firehose can handle large amounts of data ingestion with ease, and if a rogue agent starts logging large amounts of data, the Kinesis Data Firehose will deliver them without issues. This can incur large costs.
- The Kinesis Data Firehose to Elasticsearch integration is only supported for non-vpc Elasticsearch clusters.
- The Kinesis Data Firehose currently cannot deliver logs to Elasticsearch clusters that are not hosted by AWS. If you would like to self-host Elasticsearch clusters, this setup will not work.
Conclusion
If you are looking for a solution that is completely managed and (mostly) scales without intervention, this would be a good option to consider. The automatic backup to S3 with lifecycle policies also solves the log retention and archival problem easily.

Sravanthi Gottipati is Engineering Manager Email Security at Barracuda Networks. You can connect with her on LinkedIn here.
DJANGO-EB-SQS: An easier way for Django applications to communicate with AWS SQS
AWS services like Amazon ECS, Amazon S3, Amazon Kinesis, Amazon SQS and Amazon RDS are used extensively around the world. Here at Barracuda, we use AWS Simple Queue Service (SQS) to manage messaging within and among the microservices that we have developed on the Django framework.
AWS SQS is a message queuing service that can “send, store, and receive messages between software components at any volume, without losing messages or requiring other services to be available.” SQS is designed to help organizations decouple applications and scale services, and it was the perfect tool for our work on microservices. However, each new Django-based microservice or decoupling of an existing service using AWS SQS required that we duplicate our code and logic to communicate with AWS SQS. This resulted in lot of repeat code and encouraged our team to build this GitHub library: DJANGO-EB-SQS
Django-EB-SQS is a python library meant to help developers quickly integrate AWS SQS with existing and/or new Django based applications. The library takes care of the following tasks:
- Serializing the data
- Adding delaying logic
- Continuous polling from queue
- De-serializing the data as per AWS SQS standards and/or using third-party libraries to communicate with AWS SQS.
In short, it abstracts all the complexity involved in communicating with AWS SQS and lets developers focus only on core business logic.
The library is based on Django ORM framework and boto3 library.
How we use it
Our team works on an email protection solution that uses artificial intelligence to detect spear phishing and other social engineering attacks. We integrate with our customer's Office 365 account and receive notifications whenever they receive new emails. One of the tasks is to determine if the new email is clean from any fraud or not. On receiving such notifications, one of our services (Figure1: Service 1) talks to Office 365 via Graph API and gets those emails. For further processing of those emails and to make the emails available for other services, those emails are then pushed to AWS SQS queue (Figure1: queue_1).
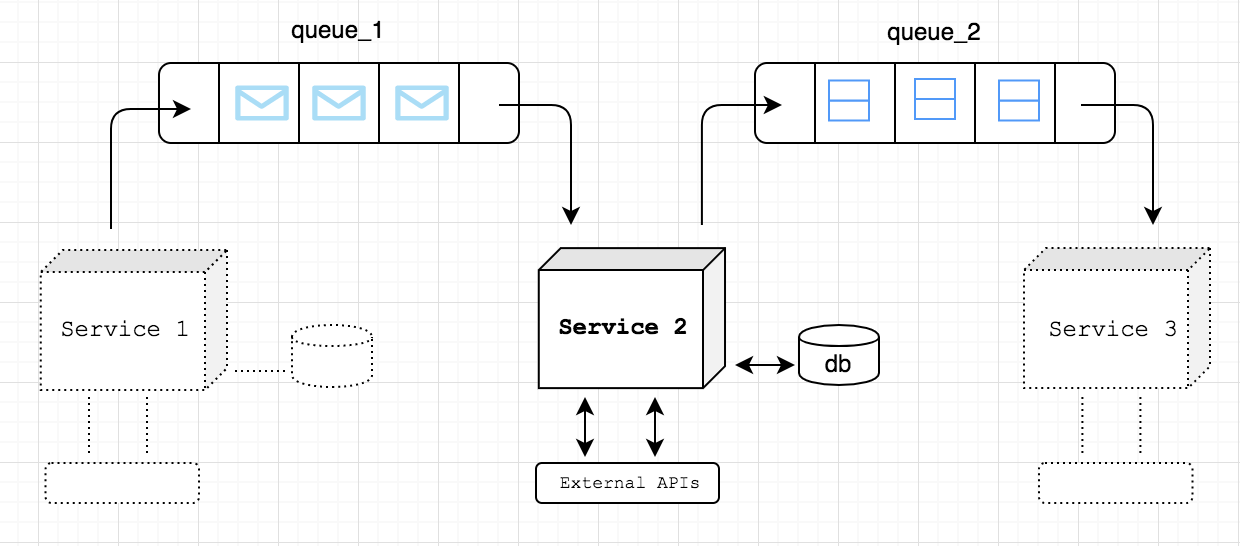
Figure 1
Let’s look at a simple use case on how we use the library in our solutions. One of our services (Figure 1: Service 2) is responsible to extract headers and feature sets from individual emails and make them available for other services to consume.
Service 2 is configured to listen to queue_1 to retrieve the raw email bodies.
Let's say that Service 2 performs the following actions:
# consume email messages from queue_1
…
# extract headers and feature sets from emails
…
# submit a task
process_message.delay(tenant_id=, email_id=, headers=, tenant_id=, feature_set=, ….)
This process_message method won’t be called up synchronously, instead it will be queued up as a task and will get executed once one of the workers picks it up. The worker here could be from same service or from a different service. The caller of the method need not worry about the underlying behavior and how the task will get executed.
Let’s look at how the process_message method is defined as a task.
from eb_sqs.decorators import task
@task(queue_name='queue_2′, max_retries=3)
def process_message(tenant_id: int, email_id: str, headers: List[dict], feature_set: List[dict], …) :
try:
# perform some action using headers and feature sets
# also can queue up further tasks, if required
except(OperationalError, InterfaceError) as exc:
try:
process_message.retry()
except MaxRetriesReachedException:
logger.error(‘MaxRetries reached for Service2:process_message ex: {exc}')
When we decorate the method with the task decorator, what happens underneath is that it adds extra data like the calling method, target method, its arguments, and some additional metadata before it serializes the message and pushes it to the AWS SQS queue. When the message is consumed from the queue by one of the workers, it has all the information needed to execute the task: which method to call, which parameters to pass, and so on.
We can also retry the task in case of an exception. However, to avoid an infinite loop scenario, we can set an optional parameter max_retries where we can stop processing after we reach the maximum number of retries. We can then log the error or send the task to a dead letter queue for further analysis.
AWS SQS gives the ability to delay the processing of the message up to 15 mins. We can add similar capability to our task by passing the delay parameter:
process_message.delay(email_id=, headers=, …., delay=300) # delaying by 5 min
Executing the tasks can be achieved by running the Django command process_queue. This supports listening to one or more queues, reading from the queues indefinitely and executing the tasks as they come in:
python manage.py process_queue –queues
We just saw how this library makes communication within service or between services easy via AWS SQS queues.
More details on how to configure the library with Django settings, and ability to listen to multiple queues, development setup and many more features can be found here.
Contribute
If you wish to contribute to the project, please refer here: DJANGO-EB-SQS

Rohan Patil is a Principal Software Engineer at Barracuda Networks. Currently he is working on Barracuda Sentinel, an AI based protection from phishing and account takeover. He has worked last five years on cloud technologies and the past decade in various roles around software development. He holds a Masters in Computer Science from California State University and Bachelors in Computers from Mumbai, India.
Using GraphQL for robust and flexible APIs
API design is an area where there can be a lot of contention between client application developers and backend developers. REST APIs enabled us to design stateless servers and structured access to resources for over two decades, and it continues to serve the industry, mainly due to its simplicity and moderate learning curve.
REST was developed around the year 2000 when client applications were relatively simple and the development pace was not as fast as it is today.
With a traditional REST-based approach, the design would be based on the concept of resources a given server manages. Then, we would typically rely on HTTP verbs such as GET, POST, PATCH, DELETE to perform CRUD operations on those resources.
Since the 2000s, several things have changed:
- Increased usage of single-page applications and mobile applications created a need for efficient data loading.
- Many of the backend architectures have turned from monolithic to µservice architectures for faster and more efficient development cycles.
- A variety of clients and consumers are needed for APIs. REST makes it hard to build an API that supports multiple clients, as it would return a fixed data structure.
- Businesses expect to rollout features faster to the market. If a change needs to be done on the client-side, it often requires a server-side adjustment with REST, leading to slower development cycles.
- Increased attention on user experience often leads to designing views/widgets that need data from multiple REST API resource servers to render them.
GraphQL as an alternative to REST
GraphQL is a modern alternative to REST that aims to solve several shortcomings, and its architecture and tooling are built to offer solutions for contemporary software development practices. It allows clients to specify exactly what data is needed and allows fetching data from multiple resources in a single request. It works more like RPC, with named queries and mutations instead of standard HTTP-based mandatory actions. This puts control where it belongs, with the backend API developer specifying what is possible, and the client/API consumer specifying what is required.
Here is a sample GraphQL query, which was an eye-opener for me when I first came across this. Assume that we are building a microblogging website, and then we need to query for 50 recent posts.
query recentPosts(count: 50, offset: 0) {
id
title
tags
content
author {
id
name
profile {
email
interests
}
}
}
The above one GraphQL query aims to request:
- Recent 50 posts
- Id, title, tags, and content for each blog post
- Author information containing id, name, and profile information.
If we have to use a traditional REST API approach for this, the client would need to make 51 requests. If posts and authors are considered separate resources, that’s one request for getting 50 recent posts and then 50 requests for getting author information for each post. If author information can be included in the post details, then this could be one request with REST API as well. But, in most cases, when we model our data using relational database normalization best practices, we would manage author information in a separate table, and that leads author information to be a separate REST API resource.
Here's the cool part with GraphQL. Say in a mobile view, we don't have real estate on screen to show both the post content and author profile information. That query could now be:
query recentPosts(count: 50, offset: 0) {
id
title
tags
author {
id
name
}
}
The mobile client now specifies the information it desires, and GraphQL API provides the exact data it’s asked for, nothing more and nothing less. We didn't have to make any server-side adjustments, nor did our client-side code have to change significantly, and our network traffic between client and server is optimal.
The point to note here is that GraphQL lets us design flexible APIs based on client-side requirements rather than from a server-side resource management perspective. A general perception is GraphQL makes sense only for complex architectures involving several dozens of µservices. This is true to some extent, given that there is some learning curve with GraphQL compared to REST API architectures. But, that gap is closing, with significant intellectual and financial investment from the emerging vendor-neutral foundation.
Barracuda is an early adopter of GraphQL architectures. If this blog has piqued your interests, please follow this space for my subsequent blogs where I will delve into more technical details and architectural benefits.

Vinay Patnana is the Engineering Manager, Email Security Service, Barracuda. In this role, he assists in the design and development of scalability services of Barracuda email solutions.
Vinay holds a Masters in Computer Science from North Carolina State University and a Bachelor of Engineering from BIT Mesra, India. He has been with Barracuda for several years and he has over a decade of experience working with several varieties of technical stacks. You can connect with him on LinkedIn here.
Note: This blog was originally published on the Databricks Company Blog.
74% of organizations globally have fallen victim to a phishing attack. Barracuda Networks is a global leader in security, application delivery and data protection solutions, helping customers fight phishing attacks at scale. Barracuda has built a powerful artificial intelligence engine that uses behavioral analysis to detect attacks to keep malicious actors at bay.
Handling phishing emails is difficult due to the sophistication attackers use in creating malicious emails nowadays. Barracuda Networks uses machine learning to assess and identify malicious messages and protect their customers. Using ML on the Databricks Lakehouse Platform, the Barracuda team has been able to move much faster and is now blocking tens of thousands of malicious emails daily from reaching millions of mailboxes across thousands of customers.
Providing Comprehensive Email Security Protection
The Barracuda team is dedicated to detecting phishing attacks and providing customer security. They achieve this by working on top of Microsoft Office 365 and analyzing the email stream for any possible threats. If an attack is detected, it is immediately removed from the mailbox before users can see it.
Impersonation Protection
One of the key products that Barracuda offers is impersonation protection. Impersonation occurs when malicious actors disguise their messages as coming from an official source, such as a known executive or service. Attackers can utilize this attack to access confidential information, posing a significant risk to individuals and organizations alike.
Impersonation protection is focused on deterring targeted phishing attacks. Such attempts are not sent in vast quantities, unlike spam emails. To send a targeted attack, the attacker must have personal details about the recipient to customize it, such as their profession or field of work. To identify and block impersonation phishing attacks, the team had to build a set of classification models and deploy them into production for our users.
Difficulties with Feature Engineering
In order to properly train our AI models to detect phishing and impersonation attacks, Barracuda needed to utilize the right data and do feature engineering on top of that data. The data included email text, which could be a signal of a phishing attack, and statistical data, such as email sender detail. For example, if a user receives an invoice email from someone who hasn't sent a similar email over the last few months, this could signal a risk of a phishing attack. Before the Databricks integration, building features was more difficult with the labeled data spread over multiple months, particularly with the statistical features. Additionally, keeping track of the features when our data set grew in size is challenging.
Slow deployment
Our team kept the code and model separate and had to duplicate research code for the production environment, which took time and energy. We would first pass each incoming email through the preprocessing code and then pass the preprocessed emails to the model for inferencing.
Barracuda Finds Success Using Databricks
The Barracuda team leveraged machine learning on the Databricks Lakehouse Platform, specifically using the Databricks Feature Store and Managed MLflow, to improve the ML process and deploy better quality models faster.
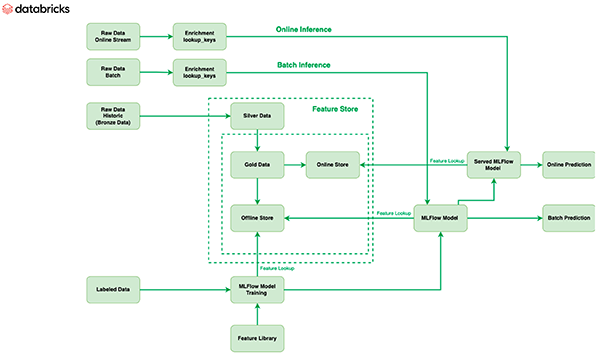
Feature Store
The Databricks Feature Store serves as the single repository for all of the features used by the Barracuda team.In order to create and maintain statistical features that are constantly updated with fresh batches of incoming emails, labeled data was employed in feature engineering. Because Feature Store is built on top of Delta, there is no extra processing required to convert labeled data to features, and the features remain current. Features are kept in an offline repository, and snapshots of this information are then released online for use in online inferencing. Additionally, by integrating Databricks Feature Store with MLflow, these features can be readily called from the models in MLflow, and the model can obtain the feature concurrently with the feature retrieval when the e-mail comes through for inferencing.
Faster Machine Learning Operations
The other advantage is managing all the machine learning models in MLflow. With MLflow, the team can move all the code inside the model , therefore, can just let the mail go through the model for inferencing instead of preprocessing through code as was being done before, making it simpler and simpler faster to infer. By using MLflow, Barracuda team is able to build fully self-packaged models. This capability greatly reduces the time the team spends developing ML models.
Higher Detection Rate
With Databricks, the team has more time and more computations – enabling them to publish a new table frequently in Delta, update the features every day, and use these to tell whether an incoming email is an attack or not. This results in higher accuracy in detecting phishing attacks and improves customer protection and satisfaction.
Impact
With the help of Databricks, Barracuda protects users from email attacks worldwide. Each day the team blocks tens of thousands of malicious emails from reaching customers' mailboxes. The team is looking forward to continuing to implement new Databricks features to enhance our customers' experience further.

{kind=link}
Mohamed Afifi Ibrahim is a Principal Machine Learning Engineer at Barracuda.